Warum Negationserkennung?
Die Erkennung von Negationen ist eine wichtige Aufgabe im medizinischen Text-Mining. Der Grund dafür liegt darin, dass bei der Behandlung von Patienten viele Untersuchungen durchgeführt werden und entsprechend sowohl das Vorhandensein als auch das Fehlen von Symptomen und auffälligen Befundergebnissen dokumentiert wird. Im Folgenden sind Beispiele für negierte Befunde.
- Patient zeigt kein Meningismus, normale Lichtreaktion, kein Hinweis auf Sklerenikterus, Mundschleimhaut und Rachenring sind reizlos und unauffällig, Schilddrüse nicht vergrößert, Übelkeit war nicht aufgetreten.
Aufgrund der Komplexität menschlicher Sprache besteht die zusätzliche Herausforderung der doppelten Verneinungen, Pseudo-Negationen etc. In den folgenden Beispielen sind Befunde nicht negiert, obwohl es deutliche Indikatorworte („unauffällig“, „nicht“, „ausgeschlossen“) im selben Satz sind.
- Abgesehen von einem leichten Hautauschlag war die körperliche Untersuchung unauffällig.
- Ein Tumor kann nicht sicher ausgeschlossen werden.
- Milz und Leber wegen Aszites nicht tastbar.
Maschinelles Lernen bildet die Grundlage für die verbesserte Negationserkennung
In regelbasierten Ansätzen werden diese komplexen Muster über eine Fülle von Regeln erkannt. Averbis verwendet hier die Text-Mining-Rule-Engine UIMA RUTA, die von Averbis entwickelt und der Community open-source zur Verfügung gestellt wird. Damit können bereits viele Verneinungsmuster zuverlässig erkannt werden.
Interne Analysen haben ergeben, dass die zuverlässige Erkennung von komplexen Verneinungsmustern zu einer enormen Komplexität in den Regeln führt und die Wartbarkeit sehr darunter leidet. Daher haben wir das regelbasierte Verfahren in den letzten Wochen um einen Machine-Learning-Ansatz ergänzt. Dafür haben wir einen großen internen Trainingsdatensatz bestehend aus englischen und deutschen Trainingsdaten zusammengestellt und annotiert. Zusätzlich wurden die Daten von dem öffentlichen i2b2-2010 Datensatz verwendet.
Das ML-Modell bekommt für jede Diagnose Informationen über die Worte vor- und nach jeder Diagnose, ob die Diagnose in einer Aufzählung ist und ob ein Negations-Indikator, wie „keine“ oder „nicht“ vorhanden ist. Die restliche Entscheidungsfindung verläuft vollautomatisch. Einzelne Fehler des ML-Modells haben wir durch gezielte Nachbearbeitungsregeln verbessert.
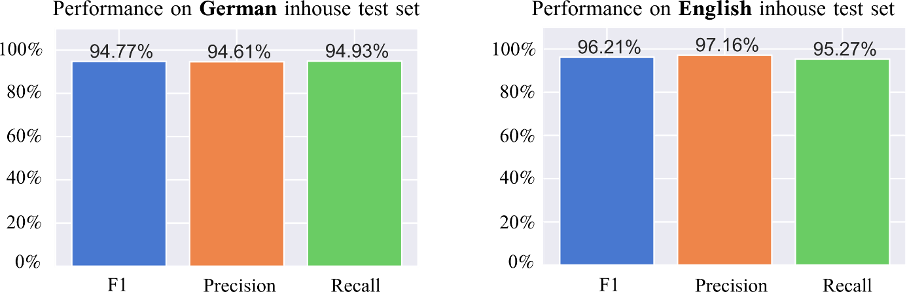
Negationsstatus von Diagnosen kann mit hoher Genauigkeit bestimmt werden
Erfreulicherweise konnten wir durch die Kombination aus regelbasiertem und ML-Verfahren die Performanz der Negationserkennung auf 96% F1-Score (englisch) bzw. 95% (deutsch) steigern. Eine tiefgehende Analyse der Fehler zeigte, dass der ML-Ansatz darüber hinaus in der Lage war, fehlerhafte Annotationen im Goldstandard zu identifizieren.